Scholar, DBLP, ORCID, SCI
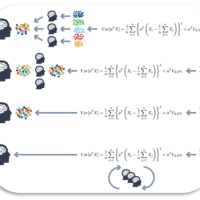
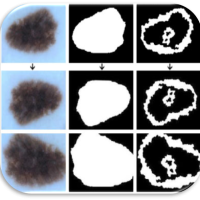
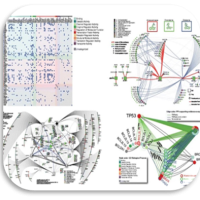
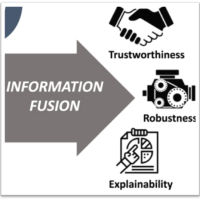
The rise of AI in domains that affect human life (agriculture, climate, forestry, health, …) needs trustful and controllable AI. Andreas Holzinger focus with his group on Human-Centered AI (HCAI) to improve robustness and explainability in order to foster trustworthy AI. Andreas promotes a synergy to enable the human-in-control to align Artificial Intelligence with human values, ethical principles and legal requirements to ensure privacy, security and safety. As large large language models like ChatGPT today show, the most pressing question of the AI community emerges “Can I trust the results?”
Subject: Computer Science (102) > Artificial Intelligence (102 001) > Machine Learning (102 019)
Keywords: Human-Centered AI (HCAI), Explainable AI (XAI), interactive Machine Learning (iML), Decision Support, trusthworthy AI, Digital Transformation
Application Areas: Domains that impact human life (agriculture, climate, forestry, health, …)
United Nations Sustainability Goals (SDG): 2, 3, 12, 13, 15
>> scroll down to see the most recent publications